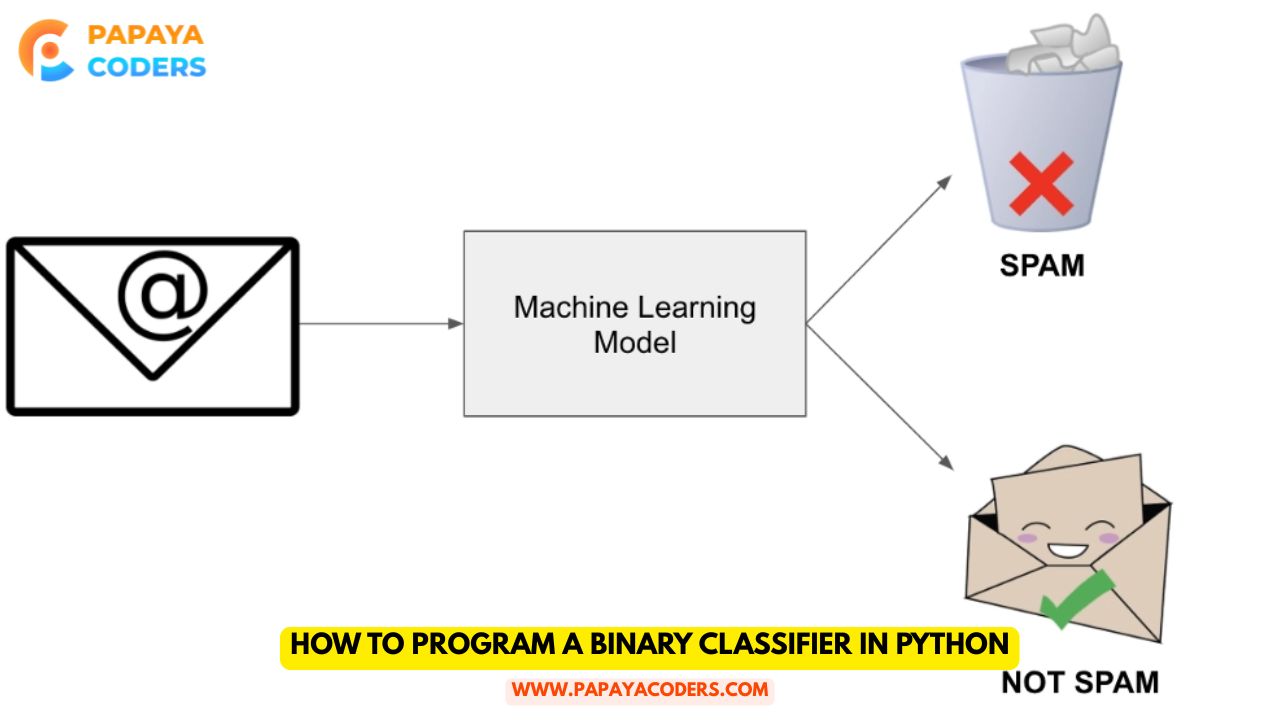
One of the most common machine learning problems is binary classification, which is basically the foundation of numerous applications like spam detection in emails, sentiment analysis, and medical diagnosis.
If you are trying to figure out how to program a binary classifier in Python, this tutorial will walk you through the whole process from concept to code in a simple and beginner-friendly manner.
Knowing Binary Classification
Binary classification is a classification task that solves the problem of dividing data into two categories. The possible categories can be “yes” or “no,” “spam” or “not spam,” “positive” or “negative,” etc. A model is given the labelled examples from which it learns, and then it is able to assign labels to new, unseen data.
A binary classifier ordinarily functions by looking at input features and figuring out the likelihood of a certain class. From a threshold (generally 0.5), it determines what class the input belongs to.
Step 1: Getting the Dataset Ready
Data is the essence of every machine learning model venture. You will require a database that has examples that are labelled. In the case of binary classification, each sample should consist of features (input variables) and a target label, which shows the class of that example, i.e., 0 and 1.
It is a good habit before you start building your classifier to make sure the data is prepared properly. The preparation process usually involves removing duplicates, fixing missing values, encoding categorical variables, and normalizing numerical values. Python libraries such as Pandas and NumPy facilitate this step in a straightforward manner.
When data is cleaned, Next splits it into two parts: training data (to teach the model) and testing data (to evaluate the performance). The commonly used proportion is 80:20, but this can be different depending on the dataset size.
Step 2: Selecting a Classification Algorithm
Python has several algorithms that can be used for binary classification. The popular choices are:
- Logistic Regression – A simple and efficient method for linearly separable data.
- Decision Tree – Can model non-linear relationships and create interpretable models.
- Support Vector Machine (SVM) – A very strong method for data with a large number of features.
- Random Forest – A method that combines several trees to reduce overfitting and increase accuracy.
- Neural Networks – For applications such as image recognition, where the problem is complex.
The beginners will find logistic regression or decision trees most suitable as a starting point because these methods are easy both to carry out and to understand.
Step 3: Creating the Model
After the selection of an algorithm, the following step is model training. Python’s scikit-learn library is very helpful here as it provides a neat and easy-to-use wrapper for this purpose. You import the model, fit it on the training data, and then make predictions.
During the training phase, the model is taught the association between the features and the labels. After training, it is capable of predicting labels for new, unseen data.
Step 4: Assessing Model Performance
A model cannot be said to be complete without an evaluation stage. The performance of the intended model should be verified through certain measures, such as:
- Accuracy – Indicates the proportion of total correct predictions.
- Precision and Recall – Measures that give more insight into the detection of minority classes.
- F1 Score – The balanced measure between precision and recall.
- Confusion Matrix – Illustrates the correct and misclassifications for each class.
Scikit-learn has functions for calculating these metrics, which you can use to figure out whether your model needs further tuning or not.
Step 5: Upgrading the Model
If the model’s performance is far from being satisfactory, there are several means to make it better, such as:
- Adjusting hyperparameters (e.g., learning rate, tree depth).
- Introducing or dropping features.
- Gathering more varied data.
Employing more sophisticated models, such as ensemble methods or deep learning.
The process of machine learning is not a one-time thing but a cycle of steps, such as training, testing, analyzing, and refining, that keeps going.
Read also:-
- What is the function of a Digital Marketing Strategist?
- How to Get Online Marketing Clients: The Complete Guide
Conclusion:-
While it may seem a little complicated at first, programming a binary classifier in Python is actually quite doable if you have the right instruments and a well-organized plan. Go through the necessary steps, starting with data preparation, then choose an appropriate algorithm, train your model with scikit-learn, and finally evaluate its performance.
Knowing binary classification coding skills is necessary if you are a data science or artificial intelligence novice who aims to predict customer churn, detect spam, or classify reviews as positive or negative. After grasping the essentials, you will find that there are infinite possibilities.