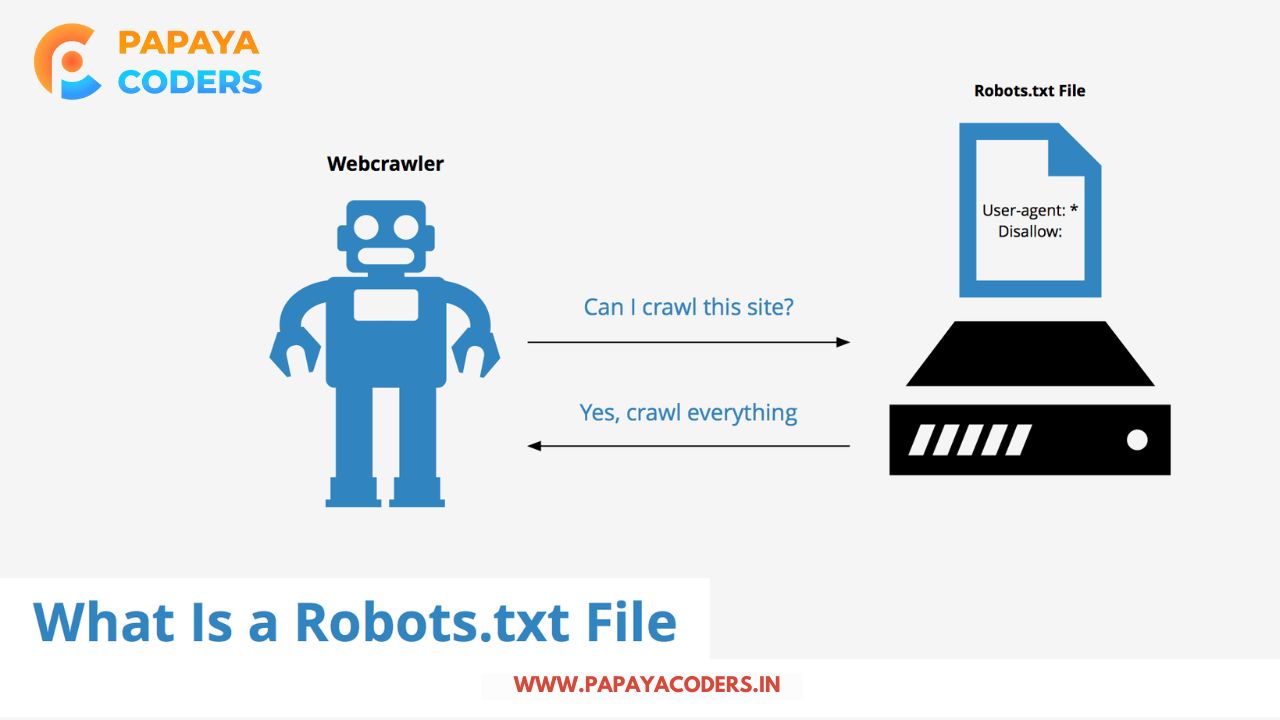
It’s the process by which search engines crawl websites to index pages and decide ranks. This process concerns visibility, but not every page should be available for crawling by these search engines. This is when the Robots TXT for SEO file comes into play- instructions for search engines telling them which parts of a website should not be crawled.
When used correctly, this small monster file can boost your SEO, improve crawl efficiency, and help you protect private content. If configured correctly, one can ensure that search engines crawl the most valuable pages of a site while ignoring those sections that fall outside the purview of ranking. Keep reading!
Understanding the Role of Robots.txt in SEO
Think of a library where search engine spiders are librarians going through thousands of books to categorize the entire library and let users know which categories are there. The index could abuse the reader completely because, after this, every single asset, from stripped-down drafts to personal notes, would have to be archived.
In this context, the robots.txt file would be a cataloging system, indicating for the digital librarians those places where the good stuff lies while also marking out places not worthy of coexistence within a public index.
Search engine spiders index pages by following links from one page to another to find where the pages belong. However, this whole crawling process takes up resources, and search engines are also limited in terms of the number of pages they can scan in a certain period.
If there are too many unimportant or irrelevant pages to crawl through, the pages are likely to include duplicate content, admin sections, and even private user data; in such cases, the bots may waste their crawling or indexing power instead of focusing on essential pages. Hence, a robots.txt file works as a direction to where these search engine crawlers should go, making the usage of resources optimal and improving search rankings.
Creating a Robots.txt File and Understanding Its Structure
Creating the robots.txt file is not very challenging, yet it requires recognition on some points. Indeed, a file of robots.txt is just a plain text file formed in the website’s leading directory. While it sounds so simple, a single error can create a mighty ruckus by shutting the right doors for good or opening otherwise hidden pieces of content for indexing.
The robots.txt file contains rules informing search engine spiders and other bots about which areas of the website they are allowed to access. Each rule has a user agent that specifies which spiders the rule is meant for and a disallow directive that gives information to the spiders on which areas they are not allowed to crawl.
Example of a Basic Robots.txt File:
User-agent: * Disallow: /admin/ Disallow: /private-data/ Allow: /public-data/public-file.html Sitemap: https://yourwebsite.com/sitemap.xml
Controlling Access to Different Areas of a Website
Not all pages on a website need to be indexed. Some areas, such as user accounts, checkout pages, or internal search results, do not contribute to search rankings and may even cause duplicate content issues. The robots.txt file provides a way to block these pages, ensuring that search engines only focus on valuable content.
Consider an online store with thousands of product pages. If internal search results are indexed, they may lead to duplicate content problems, as multiple URLs could point to the same products. Using robots.txt to disallow the indexing of search result pages, the website prevents unnecessary crawling and focuses on primary product listings.
Similarly, the file can restrict access to those sections if a blog contains draft posts or outdated content that should not appear in search results.
Enhancing SEO with Robots.txt and Sitemaps

The robots.txt file, besides blocking unwanted crawling, can enhance SEO when used along with the sitemap. Search engines depend on the sitemap to discover and give importance to valuable pages. Website owners enable search engines to locate and index their valuable content by including a sitemap link in robots.txt.
Avoiding Costly Mistakes with Robots.txt
While robots.txt can be a powerful tool, incorrect configurations can lead to serious SEO problems. Accidentally blocking critical pages may prevent them from appearing in search results, leading to a drop in traffic and visibility. Reviewing and testing robots.txt settings before implementation is essential to avoid such issues.
Another mistake involves blocking essential resources like JavaScript or CSS files. If search engines cannot access these files, they may not be able to render pages correctly, leading to lower rankings. Additionally, restricting image directories can impact image search traffic, reducing visibility for visual content.
Before finalizing changes, testing the robots.txt file using Google Search Console or similar tools ensures that the correct pages are accessible while restricted areas remain hidden. These tools allow website owners to check how search engines interpret the file and catch potential errors before they affect rankings.
Read also:
- How Much Can a Fresher Earn in Digital Marketing ??
- How can You Category Digital Marketing: Like a Pro!
Keeping Robots.txt Updated as Websites Evolve
Content & structure change as websites grow, making it necessary to update robots.txt regularly. A file that was effective in the past may become outdated as new pages are added, old sections are removed, or SEO strategies shift. Monitoring site performance and search engine behavior helps determine whether adjustments are needed.
Regularly reviewing robots.txt ensures that it continues to guide search engine crawlers efficiently. If new content needs to be indexed, restrictions can be lifted, while unnecessary areas remain private. Keeping the file updated prevents indexing issues and maintains a strong SEO foundation.

Making the Most of Robots.txt for SEO
A robots.txt file, correctly done, will work as a powerful SEO instrument by telling search engines which important content to pay attention to while preventing other pages from showing in search results. This file must be well constructed to help the server crawl efficiently, load pages faster, and prevent duplicate pages. By avoiding common mistakes and regularly examining their settings, search engines will focus on essential pages, thus boosting ranking and visibility.